redis 分析
1 简介
redis是一个类似memcached的key/value存储系统,它支持存储的value类型相对较多,包括string(字符串)、list(链表)、set(集合)和zset(有序集合)。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
2 分析
2.1 协议
本文是基于当前最新版本redis 1.2.6版本进行阅读分析的,支持的主要功能协议列表如下:
| string | get/set/setnx/del/exists/incr/decr/mget |
| list | rpush/lpush/rpop/lpop/llen/lindex/lset/lrange/ltrim/lrem/rpoplpush |
| set | sadd/srem/smove/sismember/scard/spop/srandmember/
sinter/sinterstore/sunion/sunionstore/sdiff/sdiffstore/smembers |
| zset | zadd/zincrby/zrem/zremrangebyscore/zrange/zrangebyscore/
zcount/zrevrange/zcard/zscore/incrby/descrby/ |
| select/move/rename/renamenx/expire/expireat/sort/sync |
请求采用文本协议,整体分为两种:non-bulk(不带二进制数据)和multi-bulk(带二进制数据的)协议,具体协议格式分别如下:
| non-bulk |
| command argv … argv bulk_len\r\n |
|
bulk_data\r\n |
2.2 总体结构
程序运行的主流程如下图所示:
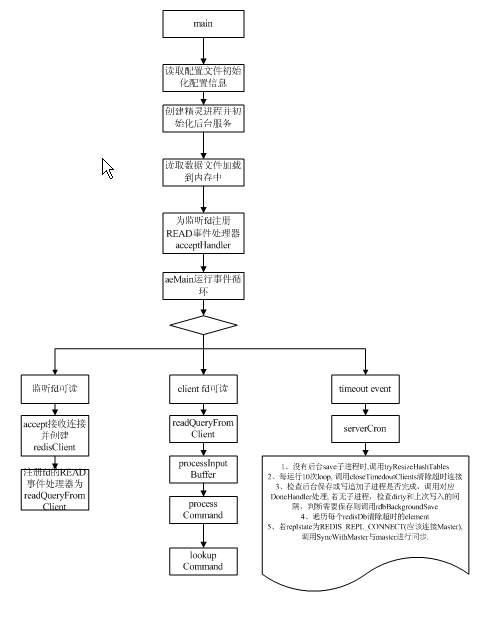
2.3 事件循环
redis网络实现没有采用开源的网络框架,具体的源文件为ae.h和ae.c。用aeEventLoop保存基于事
件系统的事件主循环,把event分为句柄事件(FileEvent)和超时事件(TimeEvent),用aeFiredEvent保存激活后的fd和event。相关的数据结构如下:
/* File event structure */
typedef struct aeFileEvent {
int mask; /* one of AE_(READABLE|WRITABLE|EXCEPTION) */
aeFileProc *rfileProc;
aeFileProc *wfileProc;
aeFileProc *efileProc;
void *clientData;
} aeFileEvent;
/* Time event structure */
typedef struct aeTimeEvent {
long long id; /* time event identifier. */
long when_sec; /* seconds */
long when_ms; /* milliseconds */
aeTimeProc *timeProc;
aeEventFinalizerProc *finalizerProc;
void *clientData;
struct aeTimeEvent *next;
} aeTimeEvent;
/* A fired event */
typedef struct aeFiredEvent {
int fd;
int mask;
} aeFiredEvent;
/* State of an event based program */
typedef struct aeEventLoop {
int maxfd;
long long timeEventNextId;
aeFileEvent events[AE_SETSIZE]; /* Registered events */
aeFiredEvent fired[AE_SETSIZE]; /* Fired events */
aeTimeEvent *timeEventHead;
int stop;
void *apidata; /* This is used for polling API specific data */
} aeEventLoop;
回调接口的定义如下:
// 句柄事件回调函数
typedef void aeFileProc(struct aeEventLoop *eventLoop, int fd, void *clientData, int mask);
// 超时回调函数
typedef int aeTimeProc(struct aeEventLoop *eventLoop, long long id, void *clientData);
// 超时event删除回调函数
typedef void aeEventFinalizerProc(struct aeEventLoop *eventLoop, void *clientData);
在网络相关操作中,定义了一组公共操作接口:aeApiCreate/ aeApiFree/aeApiAddEvent/aeApiDelEvent/aeApiPoll/aeApiName。在ae_epoll.c、ae_kqueue.c和ae_select.c中,分别实现了基于epoll/kqueue和select系统调用的接口。在ae.c中会根据宏来include对应的文件,系统调用的选择顺序依次为epoll -> kqueue -> select。
事件主循环实现在aeMain中,内部会调用aeProcessEvents函数。函数内部会先调用aeApiPoll处理fd上的注册事件,若fd上有对应事件激活,调用对应的aeFileProc进行处理;然后调用processTimeEvents函数扫描超时链表处理已超时的超时事件,调用对应的回调aeTimeProc处理。需要注意的是,aeEventLoop中采用单向链表实现了超时event链表,并且插入timeEvent时没有保证按超时时刻有序,导致每次查找(aeSearchNearestTimer)离当前时间最近的timeEvent的复杂度为O(N),aeDeleteTimeEvent删除timeEvent时的复杂度也为O(N), 删除timeEvent后需要从链表开始处重新查找已超时的timeEvent。在timeEvent链表长度较长时,操作效率会相对较低。
2.4 数据结构
2.4.1 sds (字符串)
redis采用结构sdshdr和sds封装了字符串,字符串相关的操作实现在源文件sds.h/sds.c中。sdshdr
数据结构定义如下:
typedef char *sds;
struct sdshdr {
long len;
long free;
char buf[];
};
2.4.2 list(双向链表)
对list的定义和实现在源文件adlist.h/adlist.c,相关的数据结构定义如下:
// list迭代器
typedef struct listIter {
listNode *next;
int direction;
} listIter;
// list数据结构
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned int len;
listIter iter;
} list;
2.4.3 dict(hash表)
在源文件dict.h/dict.c中实现了hashtable的操作,数据结构的定义如下:
// dict中的元素项
typedef struct dictEntry {
void *key;
void *val;
struct dictEntry *next;
} dictEntry;
// dict相关配置函数
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
// dict定义
typedef struct dict {
dictEntry **table;
dictType *type;
unsigned long size;
unsigned long sizemask;
unsigned long used;
void *privdata;
} dict;
// dict迭代器
typedef struct dictIterator {
dict *ht;
int index;
dictEntry *entry, *nextEntry;
} dictIterator;
dict中table为dictEntry指针的数组,数组中每个成员为hash值相同元素的单向链表。set是在dict的基础上实现的,指定了key的比较函数为dictEncObjKeyCompare,若key相等则不再插入。
2.4.4 zset(排序set)
typedef struct zskiplistNode {
struct zskiplistNode **forward;
struct zskiplistNode *backward;
double score;
robj *obj;
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
zset利用dict维护key -> value的映射关系,用zsl(zskiplist)保存value的有序关系。zsl实际是叉数
不稳定的多叉树,每条链上的元素从根节点到叶子节点保持升序排序。如果把zsl中出现在不同层的同一个节点当作不同的节点,则整颗树上只有根节点包含多个子节点,其他的子节点都至多有一个子节点。insert时Node的指针可能会插入到多条链中,实现时保证插入的每一个元素会出现在下标为0的左子树上,因此可以通过该左子树遍历所有元素。
zsl的结构图如下所示:
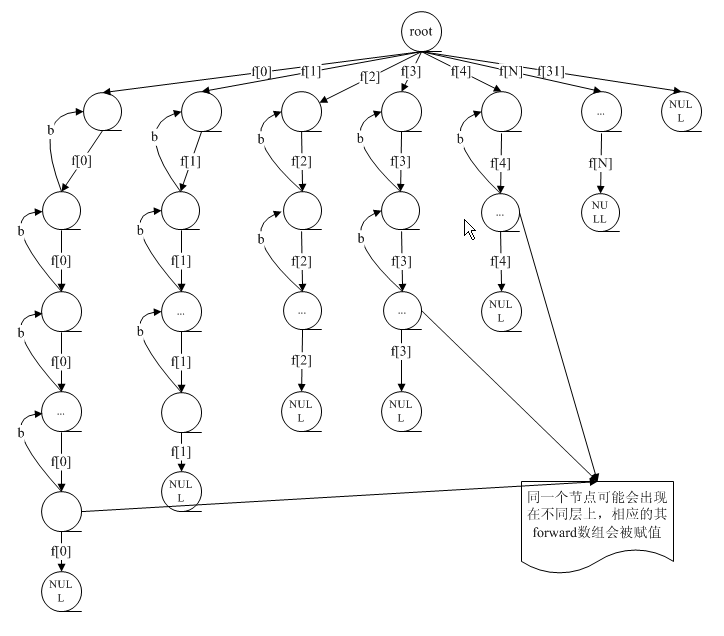
插入节点时会随机生成level,level决定了节点会插入到哪几条路径上。由于level>=1,因此每个节点都会在下标为0的路径上存在。可以看到,level越大的路径上节点数目越少。在查找>=score的节点时,利用这一特点,按照level递减的顺序从最大的level对应的路径开始查找。找到该路径上小于score的最大节点x后,对level-1转换路径从x->forward[i]继续开始查找,直到level最后减为0。返回x->forward[0],若不存在>=score的元素,则x->forward[0]为NULL。
zsl的插入过程如下图所示:
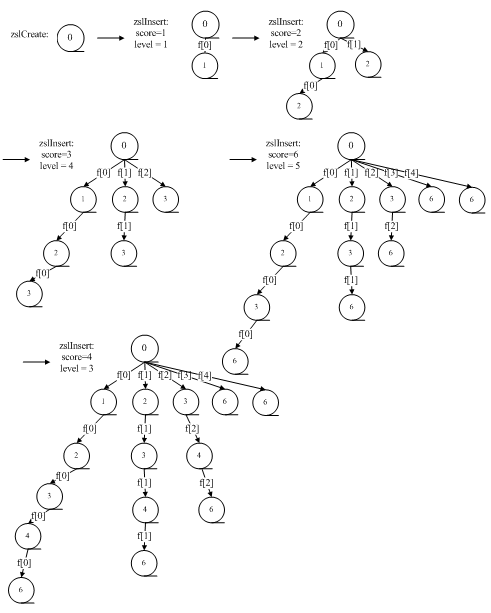
2.5 主从(master-slave)同步
启动时slave会向master发出指令SYNC进行全数据同步,slave会阻塞式等待数据同步完成加载到
内存中进行初始化后,才能开始请求处理。运行时数据同步是通过master转发请求给slave列表实现的,仅转发对数据有修改操作的请求。同步的状态机如下:

2.6 存储文件格式
redis使用了两种文件格式:全量数据和增量请求。全量数据格式是把内存中的数据写入磁盘,
便于下次读取文件进行加载;增量请求文件则是把内存中的数据序列化为操作请求,用于读取文件进行replay得到数据,序列化的操作包括SET、RPUSH、SADD、ZADD。
redis对interger根据值范围采用不同的编码存储,具体如下:
| 值范围 | 字节数(byte) | 编码格式 |
| [0, 1 << 6 – 1] | 1 | 00 | value |
| [1 << 6, 1 << 14 – 1] | 2 | 01 | (value >> 8) | value & oxFF |
| [1 << 14, 1 << 31 – 1] | 5 | 10 000000 | htonl(value) |
redis对数值类的string object编码存储格式如下:
| 值范围 | 字节数(byte) | 编码格式 |
| [-(1 << 7), 1 << 7 – 1] | 2 | 1100 0000 | value & 0xFF |
| [-(1 << 15), 1 << 15 – 1] | 3 | 1100 0001 |
(value >> 8) & 0xFF | value & oxFF |
| [-(1 << 31)], 1 << 31 – 1] | 5 | 1100 0010 |
value & oxFF | (value >> 8) & 0xFF | (value >> 16) & 0xFF | (value >> 24) & 0xFF |
redis支持字符串压缩存储,压缩的编码格式如下:
| 1100 0011 | compl_len
(压缩后的长度) |
orig_len
(压缩前的长度) |
comp_value
(压缩后的内容) |
2.6.1 data文件格式
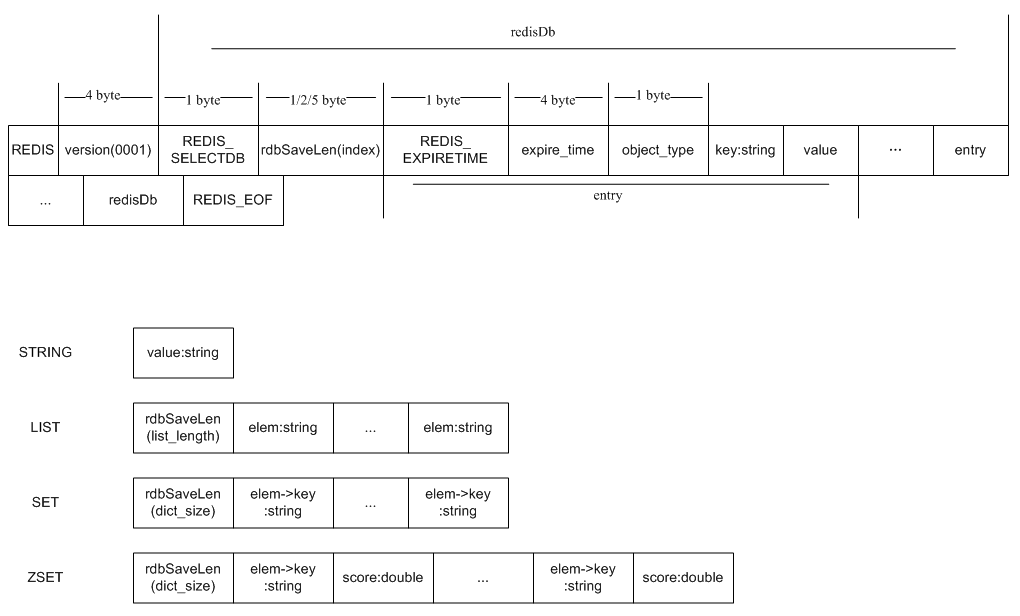
2.6.2 append文件格式
| RedisDb | *2 | $6 | SELECT | $length(index) | index:long | ||||
| entry | *3 | $3 | SET | $length(key) | key | $length(value) | value | ||
| entry | *3 | $5 | RPUSH | $length(key) | key | $length(value) | value | ||
| entry | *3 | $4 | SADD | $length(key) | key | $length(value) | value | ||
| entry | *3 | $4 | ZADD | $length(key) | key | $length(score) | score:double | $length(value) | value |
| entry | … | ||||||||
| RedisDb | … | ||||||||
| RedisDb | … | ||||||||
| entry | |||||||||
| entry | |||||||||
| entry | |||||||||
3 问题
3.1 内存泄露
在源文件hiredis.c中函数redisReadIntergerReply内部,会出现没有释放分配的内存块。
static redisReply *redisReadIntegerReply(int fd) {
// 在函数redisReadLine内部分配了sds需要的内存
sds buf = redisReadLine(fd);
redisReply *r = zmalloc(sizeof(*r));
// PROBLEM: buf为NULL时, 没有释放上面分配的redisRely指向的内存块
if (buf == NULL) return redisIOError();
r->type = REDIS_REPLY_INTEGER;
// PROBLEM: buf不为NULL时, 只是把buf的内容转化为interger, 没有释放buf指向的内存块
r->integer = strtoll(buf,NULL,10);
// FIX: 需要在这里手动调用sdsfree(buf)
return r;
}
3.2 同步机制
如2.5节所分析,redis实现的同步机制相对简单,缺少同步机制常见的check point和校验机制。
在运行时,如果master -> slave同步请求转发被丢弃, slave将无法恢复该请求的相关信息,直到slave重启时从master全量加载数据时才能修复。因此,建议使用redis尽量利用其key/value和value支持多种类型的特性,存储一些相对不重要的数据。
原文:http://www.cnblogs.com/huli/archive/2010/06/06/1752778.html
本文出自 传播、沟通、分享,转载时请注明出处及相应链接。
本文永久链接: https://www.nickdd.cn/?p=966
